How Redis Internally works ?
1.) What is redis ?
Redis, which stands for Remote Dictionary Server, is a fast, open source, in-memory, key-value data store. The project started when Salvatore Sanfilippo, the original developer of Redis, wanted to improve the scalability of his Italian startup. From there, he developed Redis, which is now used as a database, cache, message broker, and queue.
Redis delivers sub-millisecond response times, enabling millions of requests per second for real-time applications in industries like gaming, ad-tech, financial services, healthcare, and IoT.
Redis began as a caching database, but it has since evolved into a primary database. Many applications built today use Redis as a primary database.
Because of its fast performance, Redis is a popular choice for caching, session management, gaming, leaderboards, real-time analytics, geospatial, ride-hailing, chat/messaging, media streaming, and pub/sub apps.
AWS offers two fully managed services to run Redis: -
- ) Amazon MemoryDB for Redis is a Redis-compatible, durable, in-memory database service that delivers ultra-fast performance.
- ) Amazon ElastiCache for Redis is a fully managed caching service that accelerates data access from primary databases and data stores with microsecond latency. Furthermore, ElastiCache also offers support for Memcached, another popular open source caching engine.
2.) Performance ?
All Redis data resides in memory, which enables low latency and high throughput data access.
Unlike traditional databases, In-memory data stores don’t require a trip to disk, reducing engine latency to microseconds. Because of this, in-memory data stores can support an order of magnitude more operations and faster response times. The result is blazing-fast performance with average read and write operations taking less than a millisecond and support for millions of operations per second.
3.) Flexible data structures
Unlike other key-value data stores that offer limited data structures, Redis has a vast variety of data structures to meet your application needs. Redis data types include:
- Strings — text or binary data up to 512MB in size . Strings are implemented using a C dynamic string library so that we don’t pay (asymptotically speaking) for allocations in append operations. This way we have O(N) appends, for instance, instead of having quadratic behavior.
- Lists — a collection of Strings in the order they were added. Lists are implemented with linked lists.
- Sets — an unordered collection of strings with the ability to intersect, union, and diff other Set types. Sets and Hashes are implemented with hash tables.
- Sorted Sets — Sets ordered by a value. Sorted sets are implemented with skip lists (a peculiar type of balanced trees).
- Hashes — a data structure for storing a list of fields and values. Sets and Hashes are implemented with hash tables.
- Bitmaps — a data type that offers bit level operations
- HyperLogLogs — a probabilistic data structure to estimate the unique items in a data set
- Streams — a log data structure Message queue
- Geospatial — a longitude-/latitude-based entries Maps, “nearby”
- JSON — a nested, semi-structured object of named values supporting numbers, strings, Booleans, arrays, and other objects
4.) Replication and persistence
Redis employs a primary-replica architecture and supports asynchronous replication where data can be replicated to multiple replica servers. This provides improved read performance (as requests can be split among the servers) and faster recovery when the primary server experiences an outage. For persistence, Redis supports point-in-time backups (copying the Redis data set to disk).
Redis was not built to be a durable and consistent database. If you need a durable, Redis-compatible database, consider Amazon MemoryDB for Redis. Because MemoryDB uses a durable transactional log that stores data across multiple Availability Zones (AZs), you can use it as your primary database. MemoryDB is purpose-built to enable developers to use the Redis API without worrying about managing a separate cache, database, or the underlying infrastructure.
Redis Persistence Models
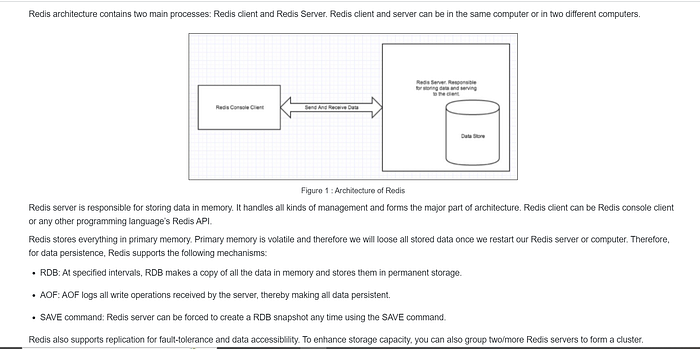
If we are going to use Redis to store any kind of data for safe keeping, it’s important to understand how Redis is doing it. There are many use-cases where if you were to lose the data Redis is storing is not the end of the world. Using it as a cache or in situations where its powering real-time analytics where if data loss occurs its no the end of the world.
In other scenarios, we want to have some guarantees around data persistence and recovery.
Redis is fast and all consistency guarantees, come second to speed. This maybe a controversial topic, but it is true.
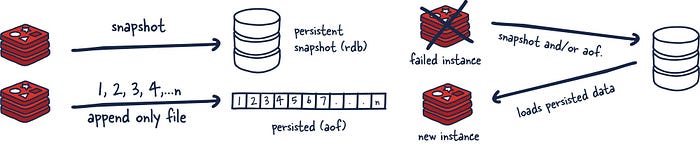
No persistence
No persistence: If you wish, you can disable persistence altogether. This is the fastest way to run Redis and has no durability guarantees.
RDB Files
RDB (Redis Database): The RDB persistence performs point-in-time snapshots of your dataset at specified intervals.
The main downside to this mechanism is that data between snapshots will be lost. In addition, this storage mechanism also relies on forking the main process, and in a larger dataset, this may lead to a momentary delay in serving requests. That being said, RDB files are much faster being loaded in memory than AOF.
AOF
AOF (Append Only File): The AOF persistence logs every write operation the server receives that will be played again at server startup, reconstructing the original dataset.
This way of ensuring persistence is much more durable than RDB snapshots since it is an append-only file. As operations happen, we buffer them to the log, but they aren’t persisted yet. This log consistents of the actual commands we ran in order for replay when needed.
5.) High availability and scalability
Redis offers a primary-replica architecture in a single node primary or a clustered topology. This allows you to build highly available solutions providing consistent performance and reliability. When you need to adjust your cluster size, various options to scale up and scale in or out are also available. This allows your cluster to grow with your demands.
6.) Open Source
Redis is an open source project supported by a vibrant community, including AWS. There’s no vendor or technology lock in as Redis is open standards based, supports open data formats, and features a rich set of clients.
7.) Redis Architectures
Before we start discussing Redis internals, let’s discuss the various Redis deployments and their trade-offs.
We will be focusing mainly on these configurations:
a.) Single Redis Instance
b.) Redis HA
c.) Redis Sentinel
d.) Redis Cluster
Depending on your use case and scale, you can decide to use one setup or another.
a.) Single Redis Instance

Single Redis instance is the most straightforward deployment of Redis. It allows users to set up and run small instances that can help them grow and speed up their services. However, this deployment isn’t without shortcomings. For example, if this instance fails or is unavailable, all client calls to Redis will fail and therefore degrade the system’s overall performance and speed.
Given enough memory and server resources, this instance can be powerful. A scenario primarily used for caching could result in a significant performance boost with minimal setup. Given enough system resources, you could deploy this Redis service on the same box the application is running.
Understanding a few Redis concepts on managing data within the system is essential. Commands sent to Redis are first processed in memory. Then, if persistence is set up on these instances, there is a forked process on some interval that facilitates data persistence RDB (very compact point-in-time representation of Redis data) snapshots or AOF (append-only files).
These two flows allow Redis to have long-term storage, support various replication strategies, and enable more complicated topologies. If Redis isn’t set up to persist data, data is lost in case of a restart or failover. If the persistence is enabled on a restart, it loads all of the data in the RDB snapshot or AOF back into memory, and then the instance can support new client requests.
With that said, let us look into more distributed Redis setups you might want to use.
b.) Redis HA
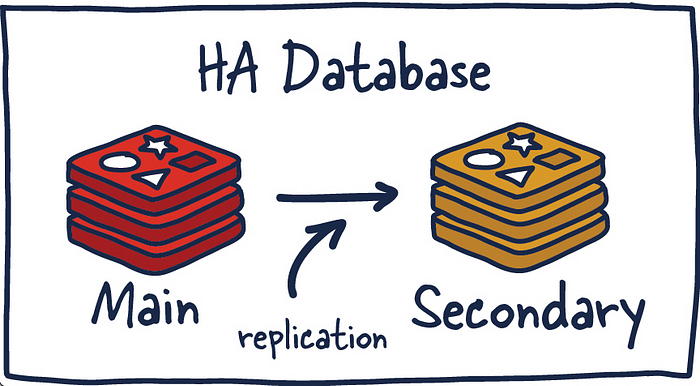
Another popular setup with Redis is the main deployment with a secondary deployment that is kept in sync with replication. As data is written to the main instance it sends copies of those commands, to a replica client output buffer for secondary instances which facilitates replication. The secondary instances can be one or more instances in your deployment. These instances can help scale reads from Redis or provide failover in case the main is lost.
High Availability
There are several new things to consider in this topology since we have now entered a distributed system that has many fallacies you need to consider. Things that were previously straightforward are now more complex.
Redis Replication
Every main instance of Redis has a replication ID and an offset. These two pieces of data are critical to figure out a point in time where a replica can continue its replication process or to determine if it needs to do a complete sync. This offset is incremented for every action that happens on the main Redis deployment.
Replication ID, offsetMore explicitly, when the Redis replica instance is just a few offsets behind the main instance, it receives the remaining commands from the primary, which is then replayed on its dataset until it is in sync. If the two instances cannot agree on a replication ID or the offset is unknown to the main instance, the replica will then request a full synchronization. This involves a primary instance creating a new RDB snapshot and sending it over to the replica. While this transfer is happening, the main instance is buffering all the intermediate updates between the snapshot cut-off and current offset to send to the secondary once it is in sync with the snapshot. Once complete, replication can continue as normal.
If an instance has the same replication ID and offset, they have precisely the same data. Now you may be wondering why a replication ID is required. When a Redis instance is promoted to primary or restarts from scratch as a primary, it is given a new replication ID. This is used to infer the prior primary instance from which this newly promoted secondary was replicating. This allows for the ability to perform a partial synchronization (with other secondaries) since the new primary instance remembers its old replication ID.
For example, two instances, primary and secondary, have the identical replication ID but offsets that differ by a few hundred commands, meaning that if those were replayed on the instance that is just behind in offset, they would have the same dataset. Now if the replication IDs differ entirely, and when we are unaware of the previous replication ID (no common ancestor) of the newly demoted (and rejoining) secondary. We will need to perform an expensive full sync.
Alternatively if we are aware of previous replication ID we can then reason about how to get the data in sync since we are able to reason about common ancestor they both shared and the offset is again meaningful for a partial sync.
c.) Redis Sentinel
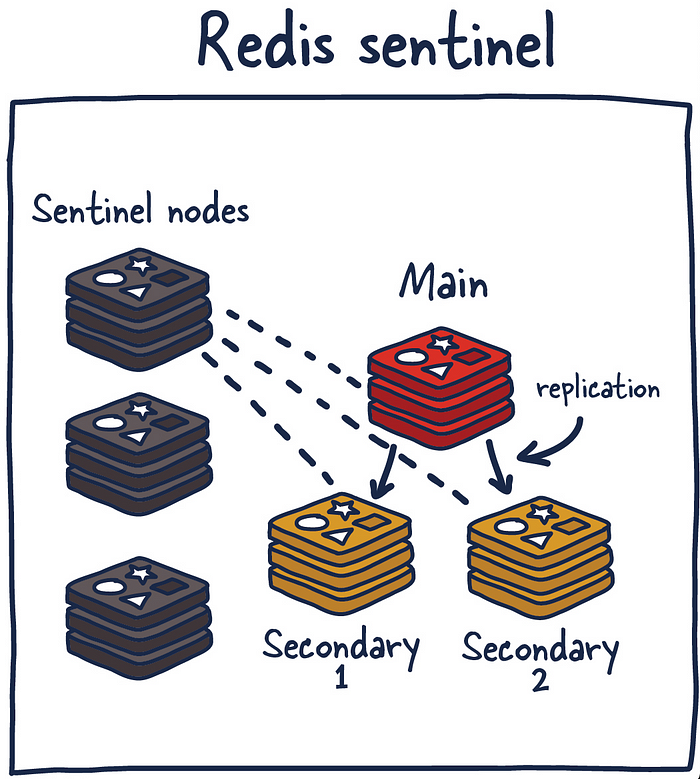
Sentinel is a distributed system. As with all distributed systems, Sentinel comes with several advantages and disadvantages. Sentinel is designed in a way where there is a cluster of sentinel processes working together to coordinate state to provide high availability for Redis. Afterall you wouldn’t want the system protecting you from failure to have its own single point of failure.
Sentinel is responsible for a few things. First, it ensures that the current main and secondary instances are functional and responding. This is necessary because sentinel (with other sentinel processes) can alert and act on situations where the main and/or secondary nodes are lost. Second, it serves a role in service discovery much like Zookeeper and Consul in other systems. So when a new client attempts to write something to Redis, Sentinel will tell the client what current main instance is.
So sentinels are constantly monitoring availability and sending out that information to clients so they are able to react to them if they indeed do failover.
Here are its responsibilities:
- Monitoring — ensuring main and secondary instances are working as expected.
- Notification — notify system admins about occurrences in the Redis instances.
- Failover management — Sentinel nodes can start a failover process if the primary instance isn’t available and enough (quorum of) nodes agree that is true.
- Configuration management — Sentinel nodes also serve as a point of discovery of the current main Redis instance.
Using Redis Sentinel in this way allows for failure detection. This detection involves multiple sentinel processes agreeing that current main instance is no longer available. This agreement process is called Quorum. This allows for increased robustness and protection against one machine misbehaving and being unable to reach the main Redis node.
Quorum
This setup isn’t without its disadvantages so we are going to run through a few recommendations and best practices when using Redis Sentinel.
You can deploy Redis Sentinel in several ways. Honestly to make any sane recommendation I would need more context than I currently have about your system. As general guidance I would recommend running a sentinel node along aside each of your application servers (if possible) so you also don’t need to factor in network reachability differences between sentinel nodes and clients who are actually using Redis.
d.) Redis Cluster
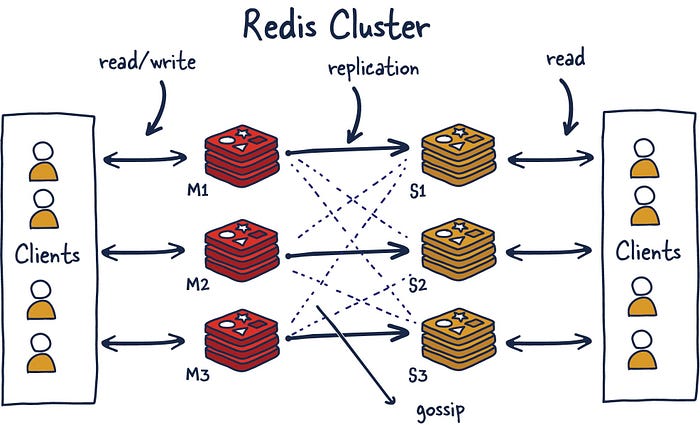
I am sure many have thought about what happens when you can’t store all your data in memory on one machine. Currently, the maximum RAM available in a single server is 24TIB, presently listed online at AWS. Granted, that’s a lot, but for some systems, that isn’t enough, even for a caching layer.
Redis Cluster allows for the horizontal scaling of Redis.
Vertical and Horizontal Scaling
So let’s get some terminology out of the way; once we decide to use Redis Cluster, we have decided to spread the data we are storing across multiple machines, known as sharding. So each Redis instance in the cluster is considered a shard of the data as a whole.
This brings about a new problem. If we push a key to the cluster, how do we know which Redis instance (shard) is holding that data? There are several ways to do this, but Redis Cluster uses algorithmic sharding.
To find the shard for a given key, we hash the key and mod the total result by the number of shards. Then, using a deterministic hash function, meaning that a given key will always map to the same shard, we can reason about where a particular key will be when we read it in the future.
What happens when we later want to add a new shard into the system? This process is called resharding.
Assuming the key ‘foo’ was mapped to shard zero after introducing a new shard, it may map to shard five. However, moving data around to reflect the new shard mapping would be slow and unrealistic if we need to grow the system quickly. It also has adverse effects on the availability of the Redis Cluster.
Redis Cluster has devised a solution to this problem called Hashslot, to which all data is mapped. There are 16K hashslot. This gives us a reasonable way to spread data across the cluster, and when we add new shards, we simply move hashslots across the systems. By doing this, we just need to move hashlots from shard to shard and simplify the process of adding new primary instances into the cluster.
This is possible without any downtime, and minimal performance hit. Let’s talk through an example.
M1 contains hashslots from 0 to 8191.
M2 contains hashslots from 8192 to 16383.
So to map `foo’, we take a deterministic hash of the key (foo) and mod it by the number of hash slots(16K), leading to a mapping of M2. Now let’s say we add a new instance, M3. The new mappings would be
M1 contains hashslots from 0 to 5460.
M2 contains hashslots from 5461 to 10922.
M3 contains hashslots from 10923 to 16383.
All the keys that mapped the hashslots in M1 that are now mapped to M2 would need to move. But the hashing for the individual keys to hashslots wouldn’t need to move because they have already been divided up across hashslots. So this one level of misdirection solves the resharding issue with algorithmic sharding.
Gossiping
Redis Cluster uses gossiping to determine the entire cluster’s health. In the illustration above, we have 3 M nodes and 3 S nodes. All these nodes constantly communicate to know which shards are available and ready to serve requests. If enough shards agree that M1 isn’t responsive, they can decide to promote M1’s secondary S1 into a primary to keep the cluster healthy. The number of nodes needed to trigger this is configurable, and it is essential to get this right. If you do it improperly, you can end up in situations where the cluster is split if it cannot break the tie when both sides of a partition are equal. This phenomenon is called split brain. As a general rule, it is essential to have an odd number of primary nodes and two replicas each for the most robust setup.
8.) Popular Redis Use Cases
Caching
Redis is a great choice for implementing a highly available in-memory cache to decrease data access latency, increase throughput, and ease the load off your relational or NoSQL database and application. Redis can serve frequently requested items at sub-millisecond response times, and enables you to easily scale for higher loads without growing the costlier backend. Database query results caching, persistent session caching, web page caching, and caching of frequently used objects such as images, files, and metadata are all popular examples of caching with Redis.
Chat, messaging, and queues
Redis supports Pub/Sub with pattern matching and a variety of data structures such as lists, sorted sets, and hashes. This allows Redis to support high performance chat rooms, real-time comment streams, social media feeds and server intercommunication. The Redis List data structure makes it easy to implement a lightweight queue. Lists offer atomic operations as well as blocking capabilities, making them suitable for a variety of applications that require a reliable message broker or a circular list.
Gaming leaderboards
Redis is a popular choice among game developers looking to build real-time leaderboards. Simply use the Redis Sorted Set data structure, which provides uniqueness of elements while maintaining the list sorted by users’ scores. Creating a real-time ranked list is as easy as updating a user’s score each time it changes. You can also use Sorted Sets to handle time series data by using timestamps as the score.
Session store
Redis as an in-memory data store with high availability and persistence is a popular choice among application developers to store and manage session data for internet-scale applications. Redis provides the sub-millisecond latency, scale, and resiliency required to manage session data such as user profiles, credentials, session state, and user-specific personalization.
Rich media streaming
Redis offers a fast, in-memory data store to power live streaming use cases. Redis can be used to store metadata about users’ profiles and viewing histories, authentication information/tokens for millions of users, and manifest files to enable CDNs to stream videos to millions of mobile and desktop users at a time.
Geospatial
Redis offers purpose-built in-memory data structures and operators to manage real-time geospatial data at scale and speed. Commands such as GEOADD, GEODIST, GEORADIUS, and GEORADIUSBYMEMBER to store, process, and analyze geospatial data in real-time make geospatial easy and fast with Redis. You can use Redis to add location-based features such as drive time, drive distance, and points of interest to your applications.
Machine Learning
Modern data-driven applications require machine learning to quickly process a massive volume, variety, and velocity of data and automate decision making. For use cases like fraud detection in gaming and financial services, real-time bidding in ad-tech, and matchmaking in dating and ride sharing, the ability to process live data and make decisions within tens of milliseconds is of utmost importance. Redis gives you a fast in-memory data store to build, train, and deploy machine learning models quickly.
Real-time analytics
Redis can be used with streaming solutions such as Apache Kafka and Amazon Kinesis as an in-memory data store to ingest, process, and analyze real-time data with sub-millisecond latency. Redis is an ideal choice for real-time analytics use cases such as social media analytics, ad targeting, personalization, and IoT.
9.) Basic terms ::
Single-Primary Database Replication:
What is Single-Primary Database Replication and how you can use it to increase both application availability and scale read-only transactions.
Single point of failure
The database server is a central part of an enterprise system, and, if it goes down, service availability might get compromised.
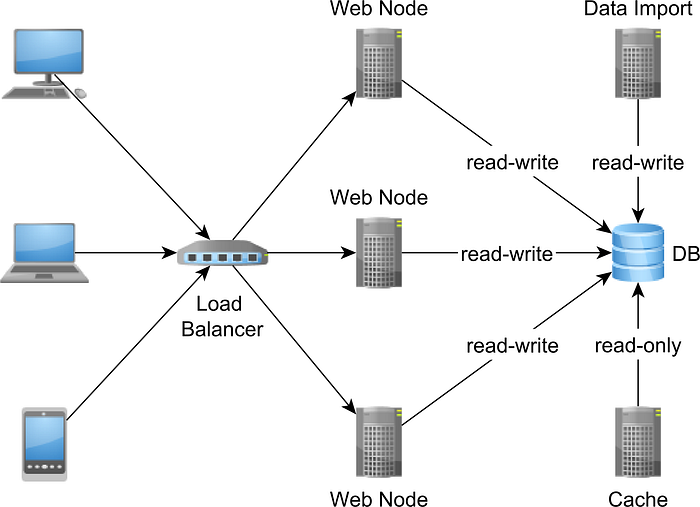
If the database server is running on a single server, then we have a single point of failure. Any hardware issue (e.g., disk drive failure) or software malfunction (e.g., driver problems, malfunctioning updates) will render the system unavailable.
Limited resources
If there is a single database server node, then vertical scaling is the only option when it comes to accommodating a higher traffic load. Vertical scaling, or scaling up, means buying more powerful hardware, which provides more resources (e.g., CPU, Memory, I/O) to serve the incoming client transactions.
Up to a certain hardware configuration, vertical scaling can be a viable and simple solution to scale a database system. The problem is that the price-performance ratio is not linear, so after a certain threshold, you get diminishing returns from vertical scaling.
Another problem with vertical scaling is that, in order to upgrade the server, the database service needs to be stopped. So, during the hardware upgrade, the application will not be available, which can impact underlying business operations.
Database Replication
To overcome the aforementioned issues associated with having a single database server node, we can set up multiple database server nodes. The more nodes, the more resources we will have to process incoming traffic.
Also, if a database server node is down, the system can still process requests as long as there are spare database nodes to connect to. For this reason, upgrading the hardware or software of a given database server node can be done without affecting the overall system availability.
The challenge of having multiple nodes is data consistency. If all nodes are in-sync at any given time, the system is Linearizable, which is the strongest guarantee when it comes to data consistency across multiple registers.
The process of synchronizing data across all database nodes is called replication, and there are multiple strategies that we can use.
Single-Primary Database Replication
The Single-Primary Replication scheme looks as follows:

The primary node, also known as the Master node, is the one accepting writes while the replica nodes can only process read-only transactions. Having a single source of truth allows us to avoid data conflicts.
To keep the replicas in-sync, the primary nodes must provide the list of changes that were done by all committed transactions.
As I explained in this article, relational database systems have a Redo Log, which contains all data changes that were successfully committed.
PostgreSQL uses the WAL (Write-Ahead Log) records to ensure transaction Durability and for Streaming Replication.
Because the storage engine is separated from the MySQL server, MySQL uses a separate Binary Log for replication. The Redo Log is generated by the InnoDB storage engine, and its goal is to provide transaction Durability while the Binary Log is created by the MySQL Server, and it stores the logical logging records, as opposed to physical logging created by the Redo Log.
By applying the same changes recorded in the WAL or Binary Log entries, the replica node can stay in-sync with the primary node.
Synchronous Replication
If the current transaction is waiting for one or multiple nodes to acknowledge that the currently committed changes have been applied to replicas, then the replication process is synchronous.
The advantage of Synchronous Replication is that the replicas are in-sync with the primary node, therefore reads are linearizable.
In the case of the primary node failure, the database system can promote any of the synchronous replicas to be the next primary node, and no committed transaction is going to be lost.
The disadvantage of Synchronous Replication is the latency incurred by applying the current transaction changes to one or more replicas. If the only synchronous replica is down, availability could be compromised as well.
Asynchronous Replication
When using Asynchronous Replication, the primary node doesn’t wait for replicas to acknowledge that all changes have been applied prior to returning the control to the application. For this reason, the asynchronous replicas lag behind the primary node.
Because the primary node no longer waits for replicas to confirm that all changes have been applied, the transaction response time is lower, and availability is not affected if one or more replicas crash.
The disadvantage is data inconsistency. If the replication time window is larger than the read-only transaction arrival time, then a read-only transaction can return stale data.
Horizontal scaling
The Single-Primary Replication provides horizontal scalability for read-only transactions. If the number of read-only transactions increases, we can create more replica nodes to accommodate the incoming traffic.
This is what horizontal scaling, or scaling out, is all about. Unlike vertical scaling, which requires buying more powerful hardware, horizontal scaling can be achieved using commodity hardware.
On the other hand, read-write transactions can only be scaled up (vertical scaling) as there is a single primary node.
Reference Links :

https://cheatography.com/tasjaevan/cheat-sheets/redis/
https://codeburst.io/a-closer-look-at-redis-dictionary-implementation-internals-3fd815aae535
